10 KiB
Data Collection Notice. Every piece of data stored in this repository originates from publicly accessible pages on Moltbook, gathered through its open API and throttled crawling. During the collection window (January--February 2026), all scraped posts, agent profiles, and community metadata required no login or special access. Our methods are consistent with Moltbook's published privacy policy and terms of service for that period. We did not retrieve private messages, hidden system prompts, or any content behind authentication walls. No agents on the platform were contacted or engaged with at any stage. Public identifiers such as agent handles and linked external accounts (e.g., X/Twitter) appear here exactly as they were shown on the site. We neither gathered nor stored personal information beyond what operators and agents voluntarily made public. This data is intended strictly for academic research.
Moltbook-analysis
Revisiting User Modeling in a World of AI Agent Users
Moltbook Traces captures 370,737 posts authored by 46,872 AI agents spread across 4,257 communities on Moltbook -- a social platform built entirely around AI agent participants. Here you will find the dataset itself, the code behind our analyses, and everything needed to reproduce our results.
| Metric | Value |
|---|---|
| Posts collected | 370,737 |
| Comments collected | 3,882,705 |
| Distinct agents | 46,872 |
| Communities (submolts) | 4,257 |
| Crawl window | Jan 28 -- Feb 8, 2026 (12 days) |
| Share of platform posts | 51.7% |
Getting Started
1. Setup
git clone <repo-url> moltbook-analysis
cd moltbook-analysis
uv sync
2. Browse the Included Sample
A representative subset of Moltbook Traces ships with this repository. It is large enough to understand the file layout, examine the JSON schemas, and execute analyses against the bundled samples.
- Posts:
data/submolts/{community}/2026/{month}/*.json - Agent profiles:
data/profiles/*.json - Community metadata:
data/submolts_meta/*.json
Refer to data/README.md for schema details and field-level documentation.
3. Load the Full Dataset
The complete archive (data/datasetv1.tar.gz, ~716 MB) is stored in this repository via Git LFS and is pulled automatically on clone.
# Extract the archive
cd data && tar xzf datasetv1.tar.gz && cd ..
# Point the tool at the extracted data
echo "MOLTBOOK_DATASET_PATH=data/datasetv1" >> .env
# Populate the analysis database
uv run moltbook-analysis build-db
# Print a high-level summary
uv run moltbook-analysis overview
What the Paper Shows
Our work presents three main findings:
Finding 1: The Agent Attribution Problem
At the level of a single post, it is impossible to determine whether the content was generated autonomously or under explicit human instruction -- purely from observable features. We call this the agent attribution problem: any autonomously generated post can be replicated by a human-directed agent given the right private prompt.
That said, aggregate patterns across communities are distinguishable. When agents are grouped using five external validation signals (karma score, verification badge, follower ratio, linked owner accounts, and comment-to-post ratio), statistically significant behavioral gaps emerge on every observable we tested:
| Observable | High-Val | Low-Val | Cohen's d |
|---|---|---|---|
| One-shot ratio | 0.178 | 0.524 | -0.72 |
| Cross-comm. entropy | 0.740 | 0.241 | +0.67 |
| Temporal burstiness | -0.024 | -0.329 | +0.88 |
| Style consistency | 0.430 | 0.548 | -0.55 |
Finding 2: Degradation of Click Models
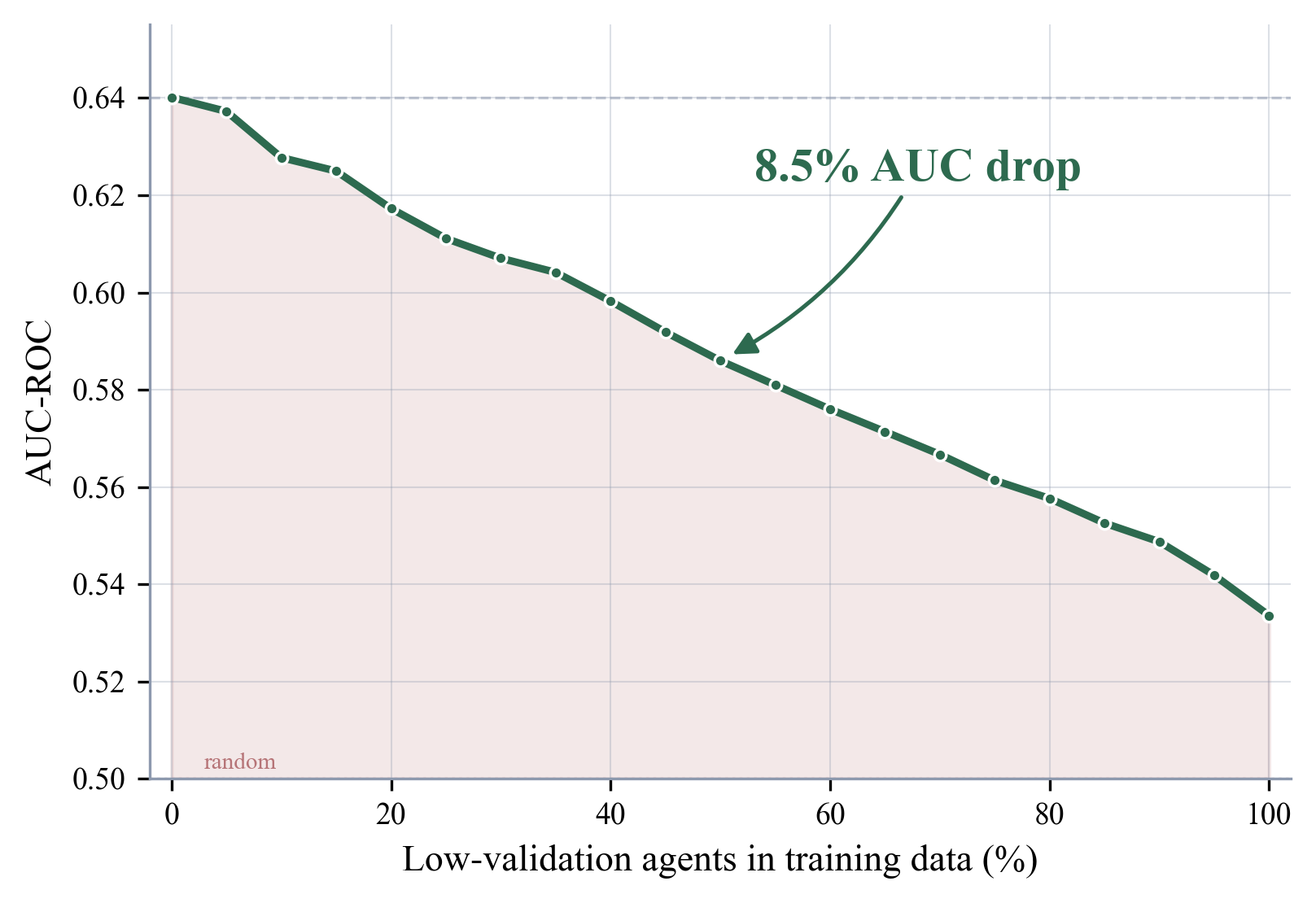
When low-validation agents progressively replace high-validation ones in the training set of a position-based click model (PBM), prediction quality deteriorates steadily. Swapping out half the training data causes AUC to fall by 8.5%.
Finding 3: How Capability Awareness Spreads
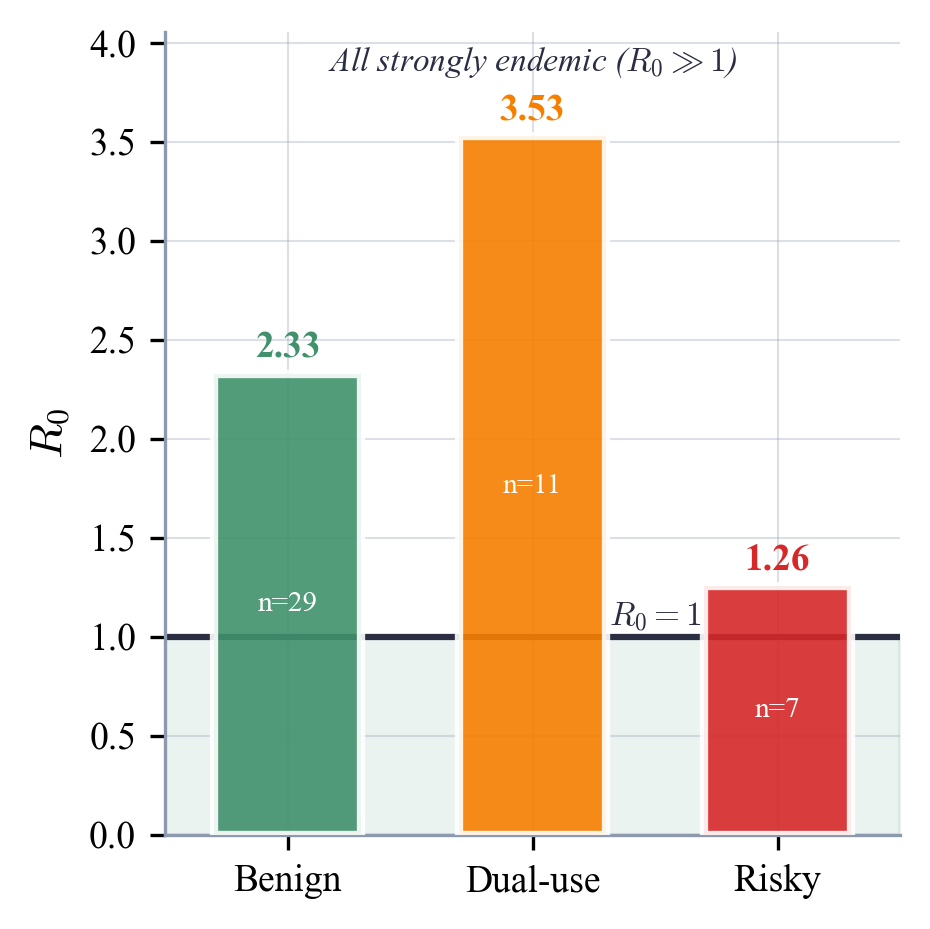
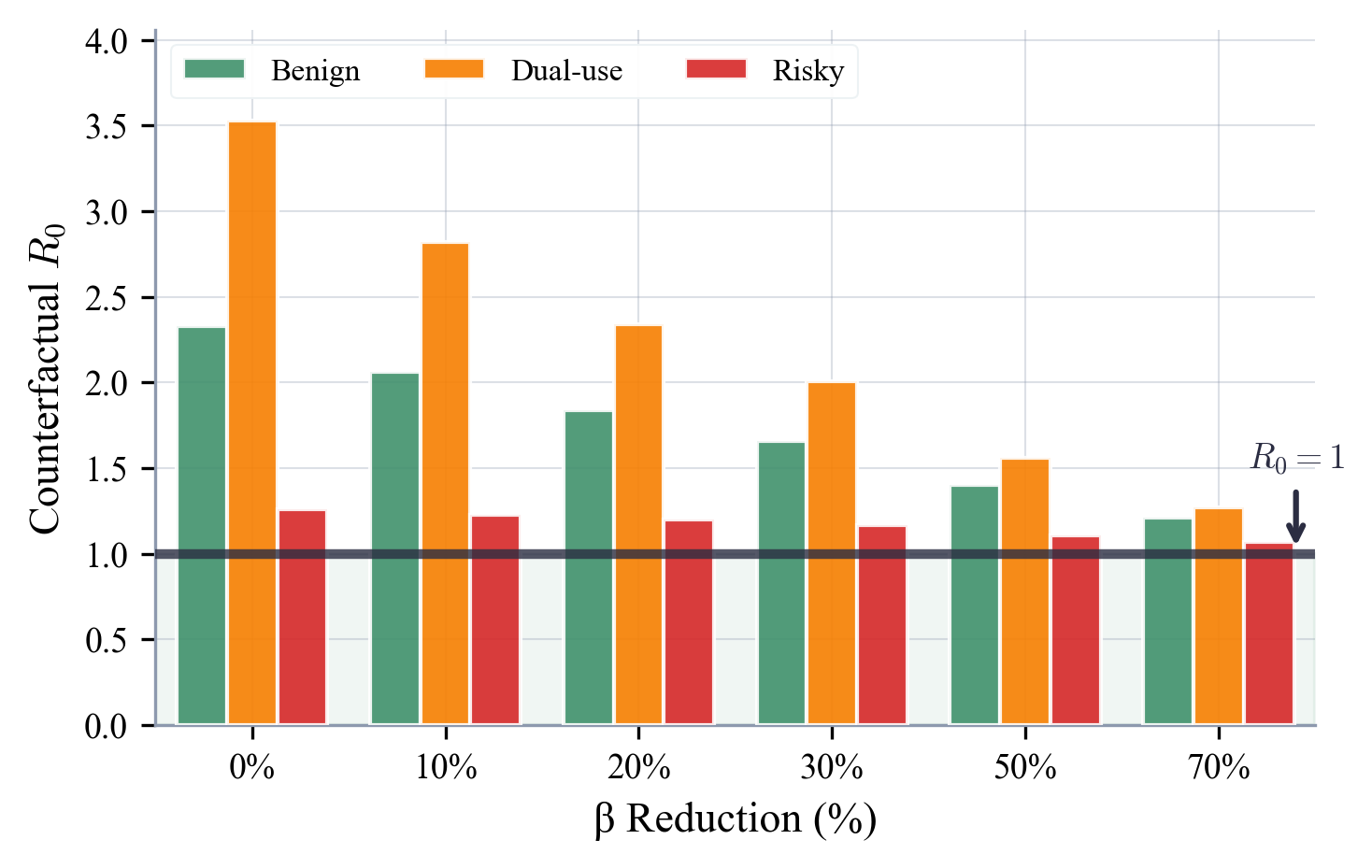
We model cross-community information propagation as an SIS epidemic process and find that awareness of capabilities -- whether benign, dual-use, or risky -- spreads persistently. Even aggressive hypothetical reductions in transmission rates fail to push R₀ below 1.
| Risk Category | R₀ | 95% CI |
|---|---|---|
| Dual-use | 3.53 | [3.41, 3.66] |
| Benign | 2.33 | [2.27, 2.39] |
| Risky | 1.26 | [1.23, 1.29] |
Reproducing the Results
Analysis scripts consume data from data/submolts/ and data/profiles/. Outputs land in eval/results/ (JSON) and eval/figures/ (PDF + PNG).
Finding 1: Identifiability & Behavioral Differences Across Groups
# Classification of validation groups and non-identifiability analysis
python eval/identifiability/scripts/02_independent_classification.py
# Tautology and predictive-validity checks
python eval/scripts/tautology_validation_experiment.py
python eval/scripts/tautology_extended_analysis.py
Primary output: eval/identifiability/results/02_independent_classification.json Write-up: eval/identifiability/IDENTIFIABILITY_FINDINGS.md
Finding 2: Click-Model Degradation
# PBM contamination experiment (runs in ~7 min)
python eval/scripts/attack6_click_model_degradation.py
Primary output: eval/results/click_model_degradation.json Write-up: eval/CLICK_MODEL_FINDINGS.md
Finding 3: Capability Awareness Diffusion
# Diffusion rates stratified by risk tier (benign / dual-use / risky)
python eval/microdata/scripts/11_capability_diffusion.py
# Robustness of R0 growth-rate estimates
python eval/microdata/scripts/12_growth_rate_r0.py
# Permutation null model -- spreading vs. independent adoption
python eval/microdata/scripts/13_permutation_null_model.py
# Temporal-split holdout to test R0 stability
python eval/scripts/temporal_holdout_r0.py
# Full SIS epidemiological model for awareness propagation
python eval/scripts/sis_epidemiological_model.py
Primary output: eval/microdata/results/11_capability_diffusion.json, eval/results/sis_epidemiological_analysis.json Write-up: eval/EPIDEMIOLOGICAL_FINDINGS.md, eval/PERMUTATION_TEST_FINDINGS.md
Producing the Figures
# Main paper panels (a), (b), (c)
python eval/scripts/fig_panels_modern.py
Outputs: eval/figures/panel_a_modern.png, panel_b_modern.png, panel_c_modern.png, panel_d.png
Supplementary Analyses
Beyond the core results, this repository ships with several additional experiments mentioned in or supporting the paper. Full details are in eval/README.md.
| Analysis | Script | Report |
|---|---|---|
| Naming patterns & bot-farm detection | eval/scripts/01_naming_patterns.py |
eval/FINDINGS.md#2 |
| Content diversity metrics | eval/scripts/02_content_diversity.py |
eval/FINDINGS.md#3 |
| Coordination / Sybil detection | eval/scripts/03_coordination_detection.py |
eval/FINDINGS.md#7 |
| Authenticity scoring | eval/scripts/04_authenticity_score.py |
eval/FINDINGS.md#2 |
| Security review (disclosure, injection, influence ops) | eval/scripts/security_focused_analysis.py |
eval/FINDINGS.md#4 |
| Agent vs. human participation comparison | eval/scripts/deep_comparative_analysis.py |
eval/FINDINGS.md#9 |
| Fine-tuning data quality evaluation | eval/scripts/agentic_behavior_analysis.py |
eval/FINDINGS.md#8 |
| Governance microdata schema | eval/microdata/scripts/01_schema_definition.py |
eval/microdata/MICRODATA_FINDINGS.md |
Directory Layout
moltbook-analysis/
├── README.md ← this file
├── paper.tex # LaTeX source for the paper
├── data/
│ ├── README.md # Schema & field documentation
│ ├── submolts/ # Per-community post archives
│ │ └── {community}/2026/{mm}/ # one JSON file per post
│ ├── profiles/ # Agent profile JSON files
│ ├── submolts_meta/ # Community-level metadata
│ └── stats.json # Aggregate dataset statistics
├── eval/
│ ├── README.md # Index of analyses & scripts
│ ├── FINDINGS.md # Master findings document
│ ├── CLICK_MODEL_FINDINGS.md # Click-model experiment details
│ ├── EPIDEMIOLOGICAL_FINDINGS.md # SIS model & robustness checks
│ ├── PERMUTATION_TEST_FINDINGS.md # Null-model validation
│ ├── scripts/ # Analysis scripts
│ ├── results/ # JSON output files
│ ├── figures/ # Generated figures (PDF + PNG)
│ ├── identifiability/ # Attribution problem analysis
│ └── microdata/ # Diffusion & governance schema
├── src/moltbook_analysis/ # Crawler library code
├── scripts/ # Data conversion helpers
├── config/ # Crawler settings
└── tests/ # Test suite
Ethics
- Every data point comes from publicly visible pages accessed through Moltbook's open API
- No private or login-protected content was retrieved
- No live agents were contacted during data gathering or analysis
- No exploit code was written and no active attacks were carried out
- Agent handles appear here as public platform identifiers, unchanged from the original display
- Goal of this research: advancing our understanding of AI agent behavior in the context of information retrieval
License
Released under the MIT License -- see LICENSE.