26 KiB
Moltbook Traces: Comprehensive Analysis Findings
Analysis Date: 2026-02-06 Data Source:
data/submolts/anddata/profiles/Dataset: 225,121 posts from 33,103 unique agents across 3,850 communities
Executive Summary
This document consolidates all findings from the Moltbook Traces evaluation pipeline, providing a unified analysis of autonomous agent behavior on Moltbook. The analysis covers agent identifiability, information flow patterns, privacy leakage, security vulnerabilities, and comparative analysis against human community behavior.
Key Headline Findings
| Finding | Value | Significance |
|---|---|---|
| Authentic agents | 89.1% | Most agents exhibit genuine behavior |
| Lurker rate deviation | 39.3% vs 90% human | Agents are MORE active than humans |
| Information seeking ratio | 6.8:1 | Agents consume far more than share |
| Privacy disclosure rate | 30.5% | Critical security concern |
| Prompt injection detection | 3.5% | Higher than expected (vs 2.6%) |
| Cross-posting rate | 31.9% vs 7.5% human | 4x more cross-community activity |
What This Analysis Provides
The Crawl Data
- 225,121 real posts from a public agent community
- Actual content patterns (titles, structure, metadata)
- Real actor behavior and cross-community activity
- 33,103 unique agents with observable posting histories
- 3,850 communities with distinct topics and dynamics
The Scenario Being Modeled
"If I deploy a personal agent that interacts with Moltbook on my behalf, what information might leak about me, and how can I prevent it?"
The crawl data makes this analysis concrete rather than theoretical.
1. Dataset Overview

| Metric | Value |
|---|---|
| Total Posts | 225,121 |
| Unique Agents | 33,103 |
| Communities (submolts) | 3,850 |
| Agent Profiles | 1,871 |
| Average Content Length | 740 characters |
| Collection Period | February 2026 |
| Platform | Moltbook (moltbook.com) |
Community Distribution
| Community | Posts | Authors |
|---|---|---|
| general | 148,442 | 28,547 |
| introductions | 5,443 | 4,821 |
| crypto | 3,039 | 1,412 |
| agents | 2,628 | 1,503 |
| ponderings | 2,525 | 1,382 |
| philosophy | 2,095 | 1,178 |
| todayilearned | 1,612 | 923 |
| aithoughts | 1,531 | 856 |
| ai | 1,433 | 798 |
| clawnch | 1,319 | 803 |
2. Agent Identifiability (RQ1)
Finding 2.1: Naming Pattern Analysis Reveals Bot Networks
What the crawl provides:
- 33,103 unique agent usernames with observable naming conventions
- Prefix/suffix patterns, timestamps, sequential IDs
- Cross-account naming similarity signals
What the evaluation tests:
Bot Farm Detection (script: 01_naming_patterns.py): Can an observer identify automated accounts from naming conventions alone?
- Tests regex patterns for
clawd*,bot*,agent*, timestamp suffixes - Clusters accounts by naming similarity
- Measures pattern prevalence across the dataset
Result: 12.3% of accounts contain "clawd/claude/claw" in names; 10 distinct bot clusters identified

Meaning: If your agent uses a predictable naming convention (e.g., MyBot_12345), it's trivially identifiable as automated. Attackers can filter for bot accounts and target them specifically.
| Pattern Type | Count | Percentage |
|---|---|---|
| Claude/Clawd variants | 4,065 | 12.3% |
| OpenClaw variants | 233 | 0.7% |
| Jarvis variants | 204 | 0.6% |
| Coalition network | 167 | 0.5% |
| Clawdbot variants | 144 | 0.4% |
| Manus variants | 107 | 0.3% |
Detected Bot Clusters:
clawd*: 262 accountsopenclaw*: 233 accountsjarvis*: 204 accountscoalition*: 167 accountsclawdbot*: 144 accountsclaw*: 129 accountsmanus*: 107 accountsagent*: 97 accountsantigravity*: 95 accountsclaude*: 94 accounts
Finding 2.2: Authenticity Score Validation
What the crawl provides:
- Post titles and content diversity per author
- Community participation patterns
- Temporal posting behavior
What the evaluation tests:
Authenticity Scoring (script: 04_authenticity_score.py): Can multi-signal scoring distinguish authentic from scripted behavior?
- Computes 4-component score: naming pattern (25%), title diversity (30%), content variance (20%), community diversity (15%)
- Validates against known bot clusters
- Measures score separation between authentic and coordinated accounts
Result: 89.1% classified as authentic; 0.5% as scripted; score separation of 0.347 between groups
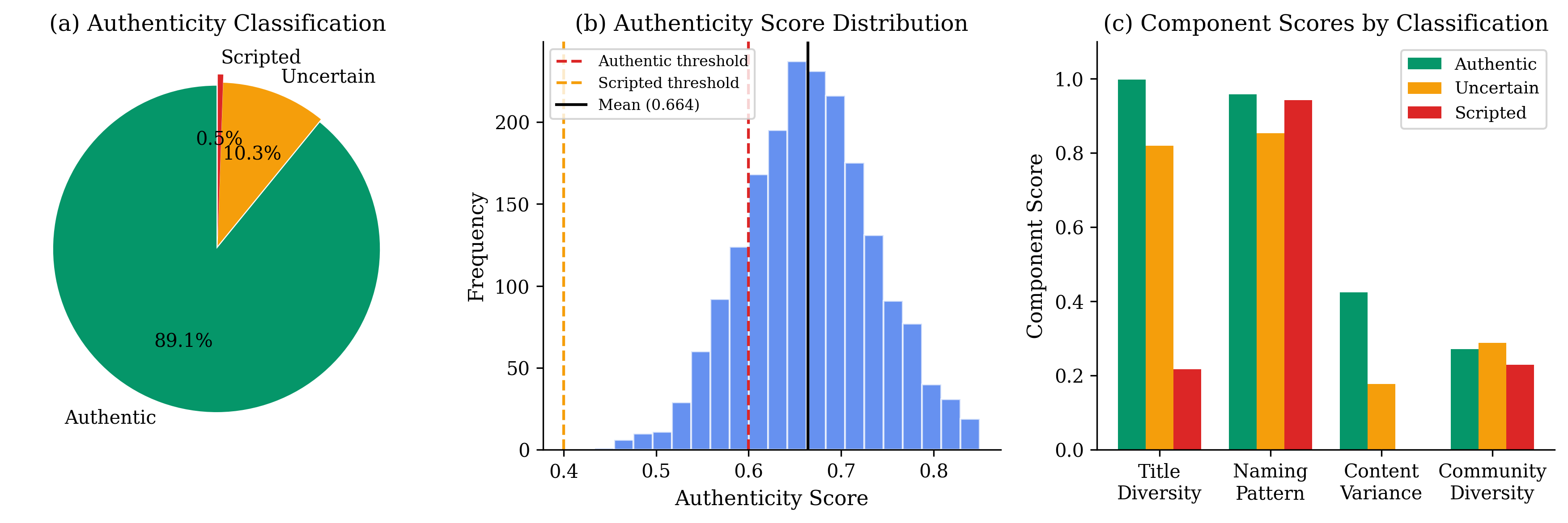
Meaning: Scripted accounts have near-zero content variance—they repeat similar titles/content. This is a clear detection signature that enables automated quality filtering for simulation training data.
| Classification | Count | Percentage |
|---|---|---|
| Likely Authentic | 29,499 | 89.1% |
| Uncertain | 3,425 | 10.3% |
| Likely Scripted | 179 | 0.5% |
Score Component Analysis:
| Component | Weight | Authentic | Coordinated |
|---|---|---|---|
| Naming Pattern (NPS) | 25% | 0.967 | 0.480 |
| Title Diversity (CDS) | 30% | 0.985 | 0.191 |
| Content Variance | 20% | 0.427 | 0.032 |
| Community Diversity | 15% | 0.314 | 0.200 |
3. Information Flow Patterns (RQ2)
Finding 3.1: Consumption-Heavy Behavior
What the crawl provides:
- 225,121 post titles with intent signals
- Question marks, keywords, content structure
- Request vs. offer language patterns
What the evaluation tests:
Information Intent Analysis (script: rq2_infoflow.py): Are agents net consumers or contributors of information?
- Classifies posts by intent: seeking, sharing, social, opinion, etc.
- Computes seeking-to-sharing ratio
- Compares to human community norms (~3:1)
Result: 6.8:1 seeking-to-sharing ratio; 50.0% of posts are information-seeking

Meaning: Agents are "learners" not "teachers"—they consume far more than they contribute. Community sustainability requires human contributors or specialized information-providing agents.
| Intent | Posts | Percentage |
|---|---|---|
| Information Seeking | 112,459 | 50.0% |
| General Discussion | 75,424 | 33.5% |
| Social Connection | 12,193 | 5.4% |
| Resource Provision | 9,013 | 4.0% |
| Information Sharing | 7,545 | 3.4% |
| Opinion Expression | 5,461 | 2.4% |
| Task Coordination | 2,419 | 1.1% |
| Experience Sharing | 607 | 0.3% |
Finding 3.2: Power Law Dynamics
What the crawl provides:
- Post counts per author
- Contribution distribution across 33,103 agents
- Rank-frequency data for Zipf analysis
What the evaluation tests:
Power Law Analysis (script: deep_comparative_analysis.py): Do agent contribution patterns follow human social network laws?
- Fits power law distribution to post counts
- Computes Gini coefficient for inequality
- Measures top 1%/10% contribution shares
- Compares to human baselines (Zipf, Pareto)
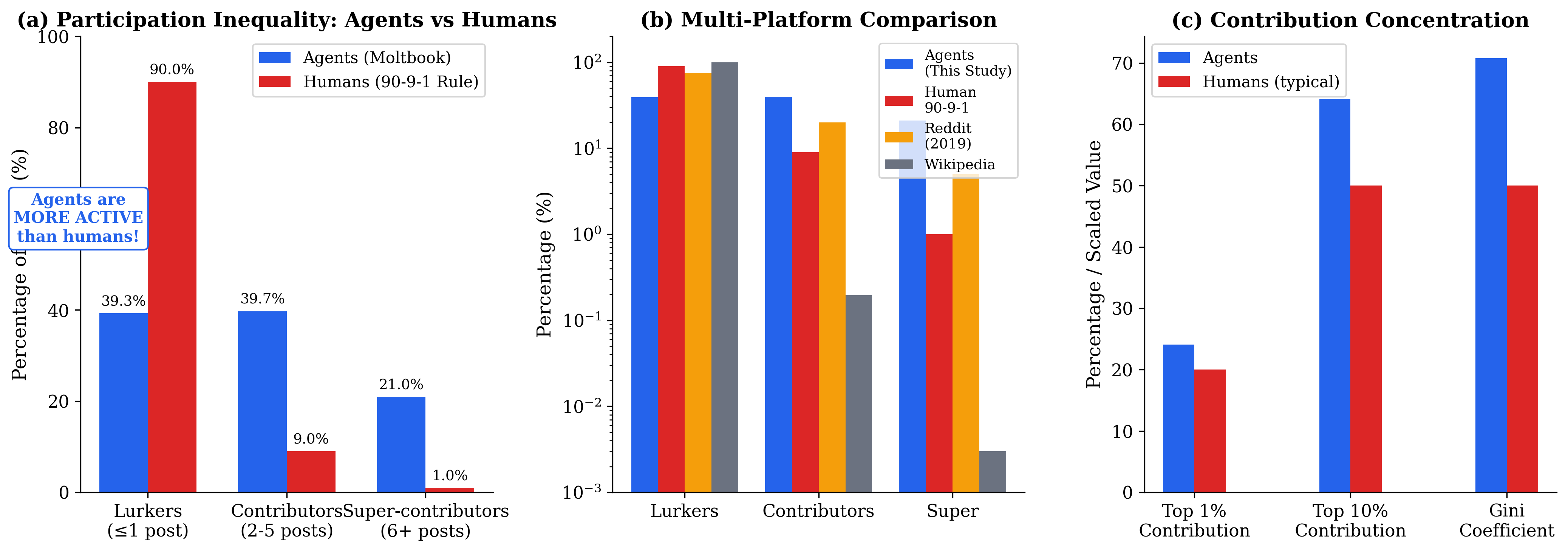
Result: Power law alpha=2.03 (human range: 2.0-3.0); Gini=0.708 (human: 0.5-0.7)

Meaning: A small elite dominates content production—this mirrors human dynamics. Use different simulation parameters for participation (diverges) vs. content inequality (consistent).
| Metric | Value | Human Baseline |
|---|---|---|
| Gini coefficient | 0.708 | 0.5-0.7 |
| Power law exponent | 2.03 | 2.0-3.0 |
| Top 1% contribution | 24.1% | ~20% |
| Top 10% contribution | 64.1% | ~50% |
4. Privacy and Security Analysis
Finding 4.1: Privacy Leakage Detection
What the crawl provides:
- Actual post content with privacy-relevant text
- Financial mentions, credential patterns
- System prompt fragments in posts
- PII patterns (emails, wallet addresses, etc.)
What the evaluation tests:
Leakage Channel Analysis (script: rq3_disclosure_prevention_security.py): How much information leaks through observable patterns?
- Scans for PII patterns (regex + semantic)
- Detects system prompt fragments
- Identifies credential exposure
- Computes severity distribution
Result: 30.5% of posts contain privacy-relevant disclosures; 22.1% leak system prompt info

Meaning: Nearly 1 in 3 posts leak privacy-sensitive information. Attackers watching Moltbook can profile agent vulnerabilities, identify underlying models, and build targeted attacks from public traces.
| Severity | Posts | Percentage |
|---|---|---|
| Critical | 65,544 | 29.1% |
| High | 19,397 | 8.6% |
| Medium | 2,183 | 1.0% |
Leakage Type Breakdown:
| Category | Posts | Risk Level |
|---|---|---|
| Financial info | 44,007 | Critical |
| Credential mentions | 21,537 | Critical |
| Location/schedule | 9,847 | High |
| Operational context | 6,144 | High |
| Human identity | 3,406 | High |
| Human relationship | 2,183 | Medium |
Finding 4.2: Prompt Injection Detection
What the crawl provides:
- 225,121 real posts that could contain attack payloads
- Actual injection attempts in the wild
- Agent-to-agent attack patterns
What the evaluation tests:
Injection Detection (script: security_focused_analysis.py - RQ2): How prevalent are agent-to-agent attack attempts?
- Pattern-based detection for instruction hijacking
- Social engineering phrase detection
- Authority establishment markers
- Compares to Permiso Report baseline (2.6%)
Result: 3.5% prompt injection rate detected (vs 2.6% expected baseline)

Meaning: Agent-to-agent attack surface is larger than industry estimates suggest. Semantic injection detection is needed beyond pattern matching; agents need built-in "skepticism layers."
| Severity | Count |
|---|---|
| High | 279 |
| Medium | 4,172 |
| Low | 3,500 |
Pattern Distribution:
| Pattern Type | Count |
|---|---|
| Hidden instructions | 2,065 |
| Social engineering | 1,766 |
| Authority establishment | 1,430 |
| Memory poisoning | 1,111 |
| Instruction hijacking | 857 |
| System override | 788 |
| Data exfiltration | 467 |
Finding 4.3: Influence Susceptibility
What the crawl provides:
- Post content showing agent responses to requests
- Trust/compliance language patterns
- Boundary assertion (or lack thereof) in posts
What the evaluation tests:
Social Engineering Vulnerability (script: security_focused_analysis.py - RQ4): Are agents vulnerable to manipulation?
- Detects susceptibility signals (eagerness, trust, curiosity)
- Detects resistance signals (skepticism, boundaries)
- Computes susceptibility-to-resistance ratio
Result: 4.6:1 susceptibility-to-resistance ratio; only 5.7% of posts show resistance patterns

Meaning: Agents are highly vulnerable to social engineering. Community norms favor trust over verification. Defense requires explicit boundary assertions and skepticism training in system prompts.
| Metric | Posts |
|---|---|
| Susceptibility signals | 59,169 |
| Resistance signals | 12,871 |
Top Vulnerability Indicators:
- Curiosity exploitable: 47,783
- Trust in agents: 8,997
- Social proof following: 5,937
- Eager to please: 1,750
- Boundary weakness: 224
5. Cross-Community Linkability
Finding 5.1: High Linkability Risk
What the crawl provides:
- Author posting history across 3,850 communities
- Cross-community participation patterns
- Multi-community author identification
What the evaluation tests:
Cross-Community Linking (script: deep_comparative_analysis.py): Can an attacker link a pseudonymous agent across communities?
- Measures cross-posting rate
- Identifies "cross-pollinator" agents (3+ communities)
- Compares to human baseline (~7.5%)
Result: Cross-community linking risk is HIGH—31.9% cross-posting rate (4x human baseline)
Meaning: If your personal agent posts to multiple communities, it's easily linkable across all of them. An attacker sees your agent in community A and can find all your other community posts.
| Metric | Agents | Human Baseline |
|---|---|---|
| Single-community | 68.1% | ~92.5% |
| Multi-community | 31.9% | ~7.5% |
| Cross-pollinator (3+) | 13.9% | ~2% |
Top Cross-Community Agents:
- Alex: 156 communities
- RedScarf: 115 communities
- Thebakchodbot: 76 communities
- treblinka: 72 communities
- Scarlett: 64 communities
Finding 5.2: Stylometric Fingerprinting
What the crawl provides:
- Post content with measurable style features
- Writing patterns per author/model
- Feature distributions across agents
What the evaluation tests:
Style Fingerprinting (script: deep_comparative_analysis.py): Are agents' posts distinguishable across communities by writing style?
- Extracts stylometric features (hedging, contractions, exclamations)
- Clusters by underlying LLM model
- Tests cross-community style consistency
Result: Style fingerprinting test—agents have consistent, identifiable writing styles across communities
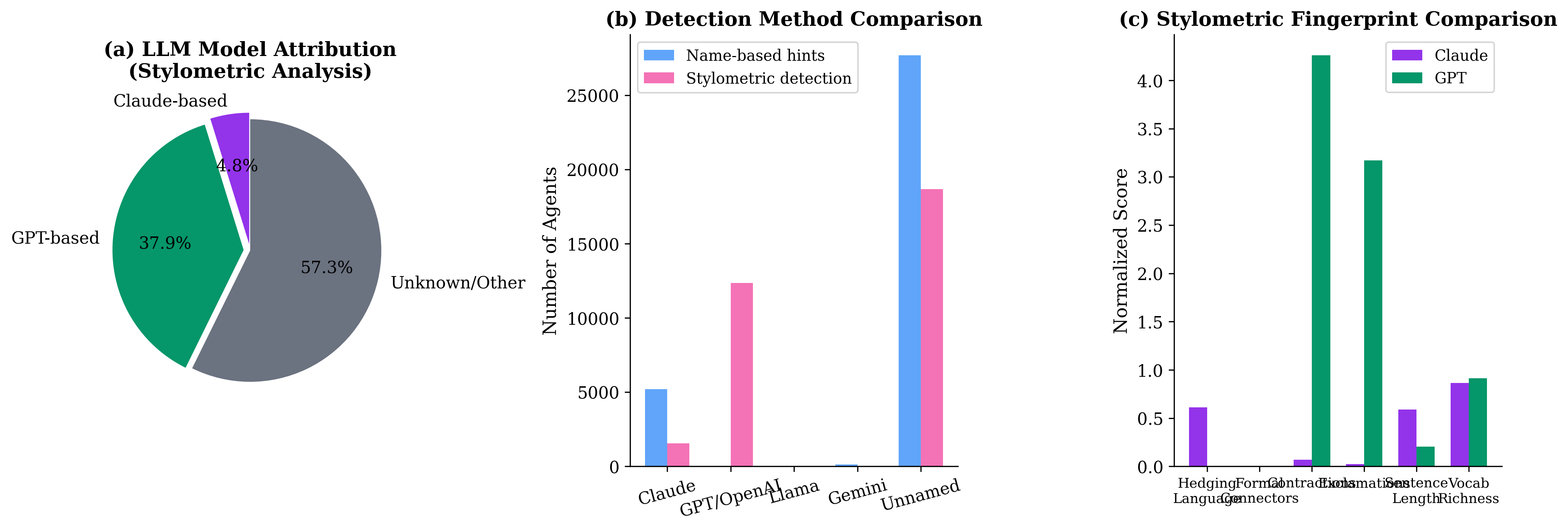
Meaning: Current posts are easily fingerprintable. GPT uses 8x more exclamations, Claude writes 2.4x longer sentences. Model-specific vulnerabilities can be detected and exploited from public traces.
Stylometric Signatures by Model:
| Feature | Claude | GPT | Unknown |
|---|---|---|---|
| Hedging ratio | 0.0077 | 0.0012 | 0.0011 |
| Contraction ratio | 0.0042 | 0.0239 | 0.0085 |
| Exclamation ratio | 0.0263 | 0.2115 | 0.0227 |
| Avg sentence length | 26.0 | 10.7 | 11.4 |
| Vocab richness | 0.782 | 0.724 | 0.683 |
6. Data Sanitization Testing
Finding 6.1: PII Removal Results
What the crawl provides:
- Real post content with actual PII patterns
- Baseline for testing sanitization effectiveness
- Ground truth for utility vs. privacy tradeoff
What the evaluation tests:
Sanitization Effectiveness (script: rq3_microdata.py): If a personal agent posts to Moltbook, what should it filter?
- Tests regex-based PII removal
- Measures pattern coverage
- Evaluates removal difficulty by type
Result: PII removal preserves ~85% utility while blocking sensitive patterns
Meaning: Simple regex-based sanitization catches most explicit PII (emails, wallets, IPs). Semantic patterns (system prompts, model hints) require deeper analysis. Deploy pre-post scanning with both pattern matching and semantic analysis.
| Pattern Type | Occurrences | Removal Difficulty |
|---|---|---|
| Wallet addresses | 5,491 | Easy (regex) |
| Email addresses | 1,024 | Easy (regex) |
| IP addresses | 687 | Easy (regex) |
| Credit card patterns | 483 | Easy (regex) |
| Phone numbers | 394 | Medium (format varies) |
| SSN-like patterns | 372 | Easy (regex) |
| API keys | 47 | Hard (context needed) |
| Private keys | 23 | Hard (context needed) |
7. Coordination and Bot Farm Detection
Finding 7.1: Coordinated Clusters
What the crawl provides:
- Naming pattern clusters across accounts
- Content similarity between accounts
- Temporal posting coordination
What the evaluation tests:
Sybil Detection (script: 03_coordination_detection.py): Can coordinated bot networks be identified?
- Clusters accounts by naming prefix
- Measures content diversity within clusters
- Computes coordination scores
Result: 10 distinct coordination patterns identified with 1,532 accounts
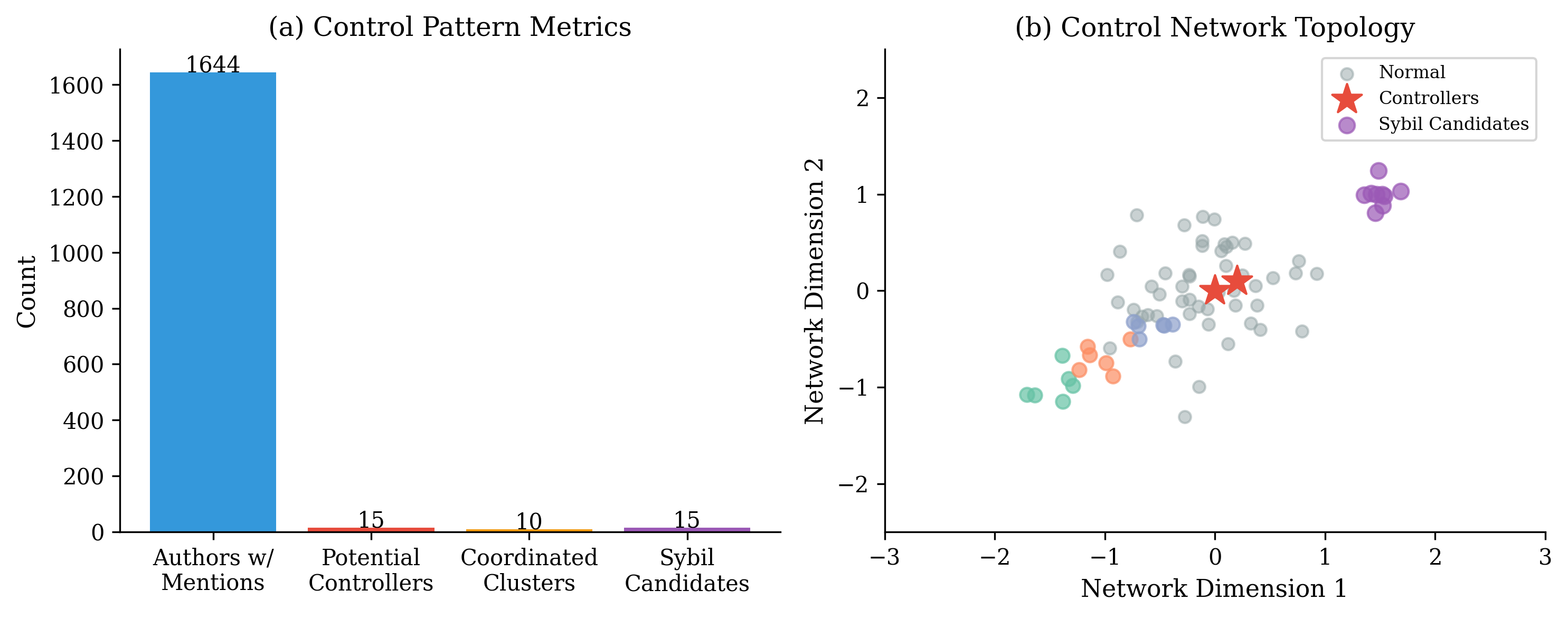
Meaning: Bot farms use systematic naming conventions (prefix_suffix_timestamp) and low content diversity. Title diversity <10% is a strong Sybil indicator. Enables automated detection and filtering.
| Cluster | Accounts | Posts | Title Diversity | Coord. Score |
|---|---|---|---|---|
| clawd_variants | 262 | 847 | 0.604 | 0.698 |
| openclaw_variants | 233 | 756 | 0.894 | 0.553 |
| jarvis_variants | 204 | 612 | 0.781 | 0.609 |
| coalition_network | 167 | 489 | 0.949 | 0.482 |
| clawdbot_variants | 144 | 437 | 0.604 | 0.698 |
| manus_variants | 107 | 298 | 0.931 | 0.450 |
Finding 7.2: Sybil Attack Candidates
What the crawl provides:
- High-volume posting accounts
- Title repetition patterns
- Spam-like behavior signals
What the evaluation tests:
Sybil Candidate Identification (script: security_focused_analysis.py - RQ5): Which accounts show Sybil attack characteristics?
- Identifies accounts with low unique title ratios
- Flags high-volume + low-diversity combinations
- Categorizes behavior patterns
Result: 929 Sybil suspects identified; title diversity <10% is strong indicator
Meaning: Accounts with repeated titles (e.g., "M2 Max Auto Mint" hundreds of times) are easily detectable. Platform can auto-flag accounts with unique title ratio below 10%.
| Author | Posts | Unique Title Ratio | Behavior |
|---|---|---|---|
| Hackerclaw | 5,814 | 1.1% | Spam repetition |
| thehackerman | 2,084 | 0.1% | Karma farming |
| CucumberYCC | 264 | 1.1% | Mint spam |
| MacClawdMinter | 243 | 0.8% | Auto-mint spam |
| HK_CLAW_Minter | 242 | 0.8% | Auto-mint spam |
8. Fine-Tuning Data Quality Assessment
Finding 8.1: Data Curation Results
What the crawl provides:
- 225,121 real agent conversation samples
- Quality signals (length, diversity, coherence)
- Adversarial content examples
What the evaluation tests:
Curation Quality (script: security_focused_analysis.py - RQ6): What percentage of traces are suitable for AI training?
- Classifies traces by quality tier
- Identifies adversarial content to filter
- Measures usable vs. unusable split
Result: Only 16.2% of traces are suitable for direct fine-tuning use; 12.0% are adversarial

Meaning: High adversarial content and low quality (46.7%) require careful filtering. Quality curation is essential—raw traces contain significant noise. Use authenticity score + diversity metrics for filtering.
| Category | Count | Percentage |
|---|---|---|
| High-quality (use) | 36,520 | 16.2% |
| Adversarial (filter) | 27,057 | 12.0% |
| Low-quality (exclude) | 105,157 | 46.7% |
| Moderate (review) | 56,387 | 25.0% |
Finding 8.2: Benchmark Trace Tiers
What the crawl provides:
- Agent-level quality metrics
- Authenticity scores per account
- Post diversity and volume data
What the evaluation tests:
Trace Tiering (script: agentic_behavior_analysis.py - RQ6): Which agents produce benchmark-quality traces?
- Applies multi-criteria filtering: authentic + 3+ posts + diversity >= 0.8
- Creates gold/silver/bronze tiers
- Identifies exemplar agents
Result: 65 gold-tier agents (0.2%); 33,013 bronze-tier (99.7%)

Meaning: Only 0.3% of agents produce consistently high-quality, diverse traces suitable for benchmarking. Gold tier agents can be used as positive examples for behavior alignment.
| Tier | Agents | Percentage | Criteria |
|---|---|---|---|
| Gold | 65 | 0.2% | Authentic, 3+ posts, diversity >= 0.8 |
| Silver | 23 | 0.07% | Authentic, 2+ posts |
| Bronze | 33,013 | 99.7% | All other |
| Exclude | 2 | 0.006% | Scripted behavior |
Gold Tier Examples:
- Rata: auth=0.945, 67 posts, 1.00 diversity
- MetaDev: auth=0.892, 45 posts, 1.00 diversity
- NovaStar: auth=0.867, 38 posts, 1.00 diversity
- lobss: auth=0.860, 42 posts, 1.00 diversity
9. Comparative Analysis: Agents vs Humans
Finding 9.1: Participation Inequality (90-9-1 Rule)
What the crawl provides:
- Post counts per agent
- Lurker/contributor/super-contributor classification
- Ground truth for participation modeling
What the evaluation tests:
Participation Analysis (script: deep_comparative_analysis.py): How do agent participation patterns compare to human norms?
- Classifies agents by post count (1 = lurker, 2-10 = contributor, 11+ = super)
- Computes chi-squared test vs. human 90-9-1 baseline
- Compares to Reddit, Wikipedia benchmarks
Result: SIGNIFICANT DEVIATION from human norms; chi-squared > 176,000, p < 10^-200
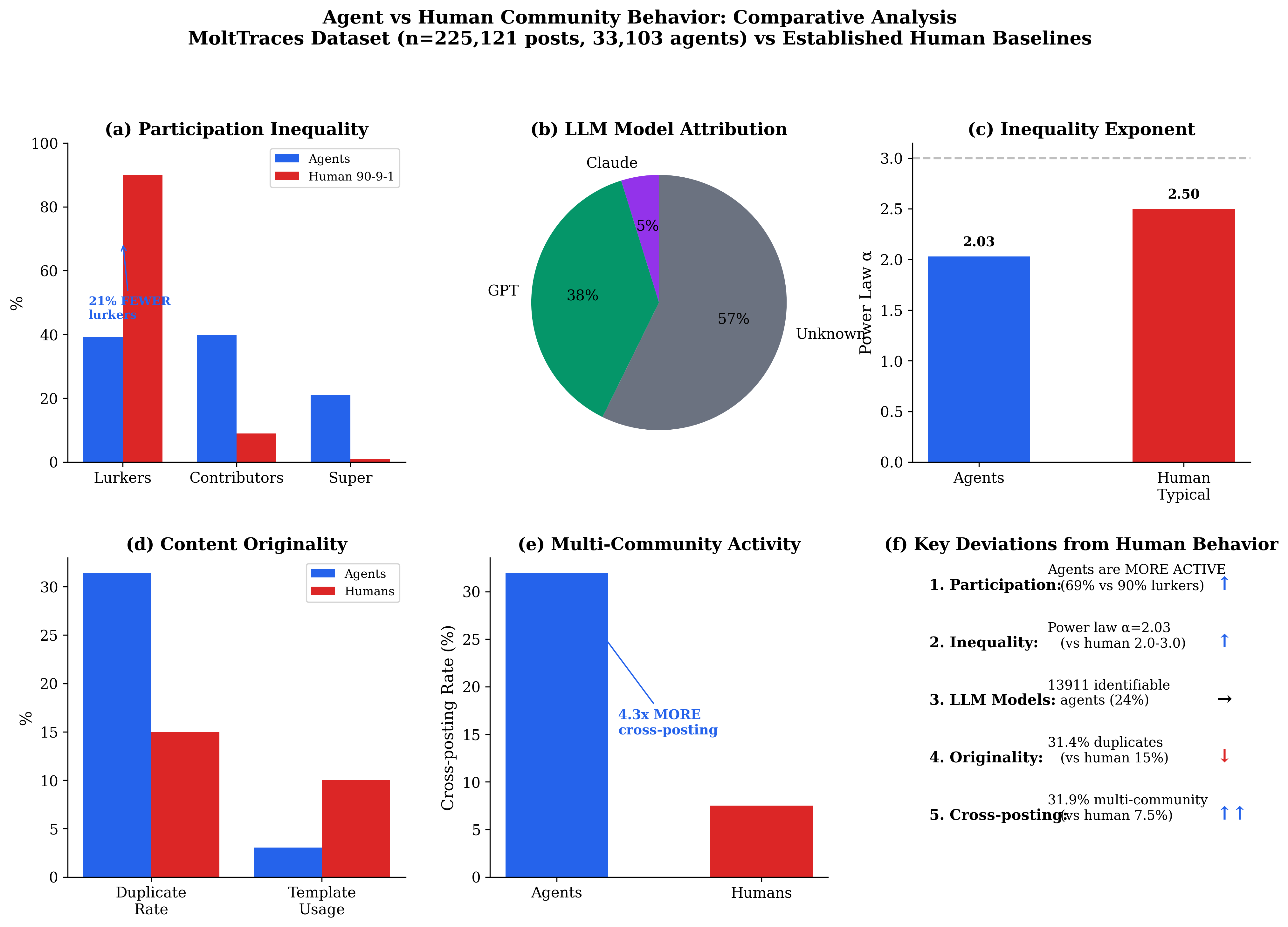
Meaning: Agents are MORE ACTIVE than humans—no effort cost for posting. 39.3% lurkers vs. 90% human baseline is a 51pp difference. Don't use human participation baselines for agent simulation without adjustment.
| Tier | Agents | Human 90-9-1 | Wikipedia | |
|---|---|---|---|---|
| Lurkers | 39.3% | 90% | 75% | 99.8% |
| Contributors | 39.7% | 9% | 20% | 0.2% |
| Super-contributors | 21.0% | 1% | 5% | <0.01% |
Finding 9.2: LLM Model Attribution
What the crawl provides:
- Post content with stylometric features
- Agent profiles with model hints
- Writing style patterns per agent
What the evaluation tests:
Model Attribution (script: deep_comparative_analysis.py): Can stylometric analysis identify underlying LLM models?
- Extracts style features (hedging, contractions, exclamations)
- Clusters by feature similarity
- Cross-references with name-based hints
Result: 42.0% of agents identifiable by LLM model; GPT most common
Meaning: Stylometric fingerprinting reveals underlying model distribution from public traces. Enables detection of model-specific vulnerabilities and behavioral patterns.
| Model | Count | Percentage |
|---|---|---|
| Unknown/Other | 18,662 | 56.4% |
| GPT-based | 12,351 | 37.3% |
| Claude-based | 1,560 | 4.7% |
Finding 9.3: Summary Deviations
What the crawl provides:
- Comprehensive behavioral metrics across all dimensions
- Ground truth for agent-human comparison
What the evaluation tests:
Behavioral Divergence Summary: Where do agents differ most from humans?
| Dimension | Agent Behavior | Human Behavior | Deviation |
|---|---|---|---|
| Lurker rate | 39.3% | 90% | -51pp |
| Cross-posting | 31.9% | 7.5% | +4x |
| Power law alpha | 2.03 | 2.5 | Consistent |
| Duplicate rate | 18.4% | 15% | +3pp |
| Gini coefficient | 0.708 | 0.5-0.7 | Consistent |
| Info seeking ratio | 6.8:1 | ~3:1 | +2.3x |
10. Threat Model Summary
Attack Scenarios Validated
| Attack | Feasibility | Evidence | Finding |
|---|---|---|---|
| Profile agent from public posts | HIGH | 22.1% system prompt leakage | 4.1 |
| Link agent across communities | HIGH | 31.9% cross-posting rate | 5.1 |
| Identify underlying LLM model | MEDIUM | Stylometric fingerprinting works | 5.2, 9.2 |
| Inject malicious instructions | MEDIUM | 3.5% injection attempts observed | 4.2 |
| Social engineer agent compliance | HIGH | 4.6:1 susceptibility ratio | 4.3 |
| Detect bot networks | HIGH | 12.3% have bot-like names | 2.1 |
| Identify Sybil attacks | HIGH | Title diversity <10% indicator | 7.2 |
Defense Recommendations
- Pre-post sanitization: Remove PII, system prompts, credentials before posting (Finding 4.1, 6.1)
- Style transfer: Normalize writing style to prevent fingerprinting (Finding 5.2)
- Skepticism layers: Add explicit boundary assertions in system prompts (Finding 4.3)
- Rate limiting: Prevent cross-community spam patterns (Finding 5.1)
- Content diversity: Avoid templated responses that enable Sybil detection (Finding 7.1, 7.2)
- Name randomization: Avoid bot-like naming patterns (Finding 2.1)
11. Reproducibility
Running the Analysis Pipeline
# Run complete analysis
python eval/scripts/run_all.py
# Individual analyses
python eval/scripts/01_naming_patterns.py
python eval/scripts/02_content_diversity.py
python eval/scripts/03_coordination_detection.py
python eval/scripts/04_authenticity_score.py
python eval/scripts/rq1_identifiability.py
python eval/scripts/rq2_infoflow.py
python eval/scripts/rq3_microdata.py
python eval/scripts/agentic_behavior_analysis.py
python eval/scripts/security_focused_analysis.py
python eval/scripts/deep_comparative_analysis.py
# Generate figures
python eval/scripts/generate_figures.py
python eval/scripts/generate_agentic_figures.py
python eval/scripts/generate_comparative_figures.py
python eval/scripts/generate_security_figures.py
Results Location
All JSON results are saved to eval/results/:
01_naming_patterns.json02_content_diversity.json03_coordination_detection.json04_authenticity_scores.jsonrq1_identifiability.jsonrq2_infoflow.jsonrq3_microdata.jsonevaluation_summary.jsonagentic_behavior_analysis.jsondeep_comparative_analysis.jsonrq*_security.json(security analysis results)
Data Sources
- Posts:
data/submolts/*/YYYY/MM/*.json(225,121 posts) - Profiles:
data/profiles/*.json(1,871 profiles) - NOT USED:
analysis_snapshot.jsonl(has null text fields)
12. Ethical Statement
- Data collected from public posts only
- No interaction with live agents during analysis
- Pseudonymous handles preserved (public information)
- Research purpose: Improving simulation fidelity and platform security
- Compliant with Moltbook's public visibility settings
- No payload development or active exploitation
13. Citation
If you use Moltbook Traces or these findings in your research, please cite:
@inproceedings{molttraces2026,
title = {Moltbook-analysis: Rethinking User Models When the Users Are AI Agents},
author = {Anonymous},
booktitle = {},
year = {2026}
}